ollama and llama.cpp installation and configuration amd rocm ubuntu 22.04
Posted: Tue Feb 04, 2025 11:06 am

Join our telegram group if you wana chat or have specific questions:
https://t.me/+h2K5CX5jEZA0MWJk
Here i will post and update all ollama and llama.cpp installation and configuration!
My test GPU:

Install llama.cpp on AMD 6950XT RocM for ubuntu 22.04
Code: Select all
sudo apt update
sudo apt install "linux-headers-$(uname -r)" "linux-modules-extra-$(uname -r)"
sudo apt install python3-setuptools python3-wheel
sudo usermod -a -G render,video $LOGNAME # Add the current user to the render and video groups
wget https://repo.radeon.com/amdgpu-install/6.3.2/ubuntu/jammy/amdgpu-install_6.3.60302-1_all.deb
sudo apt install ./amdgpu-install_6.3.60302-1_all.deb
sudo apt update
sudo apt install amdgpu-dkms rocmCode: Select all
apt-get install rocm-dev rocm-libs libstdc++-12-dev libc++-dev libc++abi-dev cmake
Code: Select all
export HSA_OVERRIDE_GFX_VERSION=10.3.0
export HIP_VISIBLE_DEVICES=0
export OLLAMA_GPU_LAYER=rocm
echo 'export HSA_OVERRIDE_GFX_VERSION=10.3.0' >> ~/.bashrc
echo 'export HIP_VISIBLE_DEVICES=0' >> ~/.bashrc
echo 'export OLLAMA_GPU_LAYER=rocm' >> ~/.bashrc
source ~/.bashrc
Code: Select all
export PATH=/opt/rocm/bin:$PATH
export HIP_PATH=/opt/rocm/hip
export HIPCXX=/opt/rocm/bin/hipcc
echo 'export PATH=/opt/rocm/bin:$PATH' >> ~/.bashrc
export HIPCXX=$(hipconfig -l)/clang
export HIP_PATH=$(hipconfig -R)
echo 'export HIPCXX=$(hipconfig -l)/clang' >> ~/.bashrc
echo 'export HIP_PATH=$(hipconfig -R)' >> ~/.bashrc
source ~/.bashrc
export HSA_XNACK=1
export HSA_ENABLE_SDMA=0
echo "export HSA_XNACK=1" >> ~/.bashrc
echo "export HSA_ENABLE_SDMA=0" >> ~/.bashrc
source ~/.bashrc
/opt/rocm/bin/rocminfo | grep "gfx"
Code: Select all
/opt/rocm/bin/hipconfig --version
Let download and build llama.cpp for AMD RocM:
Code: Select all
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
HIPCXX="$(hipconfig -l)/clang" HIP_PATH="$(hipconfig -R)" \
cmake -S . -B build -DGGML_HIP=ON -DAMDGPU_TARGETS=gfx1030 -DCMAKE_BUILD_TYPE=Release \
&& cmake --build build --config Release -- -j 16
https://github.com/ggerganov/llama.cpp/ ... s/build.md
then cd to build/bin and test with llama-cli
How llama.cpp Handles Defaults ?
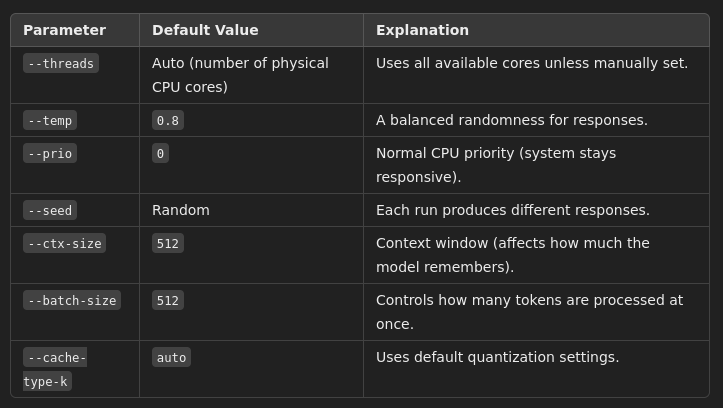
Example to test:
Max VRAM usage (may cause OOM if GPU memory is too small)
Code: Select all
./llama-cli --model "/home/Downloads/DeepSeek-R1-Distill-Qwen-14B-Q8_0.gguf" --n-gpu-layers 60Code: Select all
./llama-cli -m /media/models/Users/user/.lmstudio/models/unsloth/DeepSeek-R1-Distill-Llama-70B-GGUF/DeepSeek-R1-Distill-Llama-70B-Q4_K_M.gguf \
-t 32 \
--ctx-size 8192 \
-n 2048 \
-b 2048 \
-ub 512 \
--device ROCm0 \
--gpu-layers 28 \
--split-mode layer \
--numa distribute
youtu.be/ObOVTg-1j7I
Run Full Deepseek model 671B on CPU only here is how:
https://threadreaderapp.com/thread/1884 ... 78106.html
and
https://digitalspaceport.com/how-to-run ... -epyc-rig/
Another variant with full model but moded a little to fit 128GB ram !
https://unsloth.ai/blog/deepseekr1-dynamic
youtu.be/Tq_cmN4j2yY
youtu.be/_PxT9pyN_eE